Puppeteer 使用小记
Puppeteer 实战小记——教你如何使用 Puppeteer 来完成模拟登录+抓取数据。
Puppeteer 简介
网上关于 Puppeteer 介绍资料很多,所以这里就不过多展开了。只说两点。
第一,与 Puppeteer 类似的技术很多,早期主要是 Phantom.js。不过随着Google 在 Chrome 59版本开始支持 headless 模式,Ariya Hidayat 决定放弃对 Phantom.js 的维护
我原本尝试使用 PhantomJS 完成模块登录和抓取数据工作,但遇到了一点问题(问题原因未深究),随后果断换到 Puppeteer。
第二,Puppeteer 是一个提供高级别API的 Node 库,简化 headless Chrome 的使用。
Puppeteer(Puppeteer is a Node library which provides a high-level API to control headless Chrome over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome.)
这张图展示了 Puppeteer 的全貌。
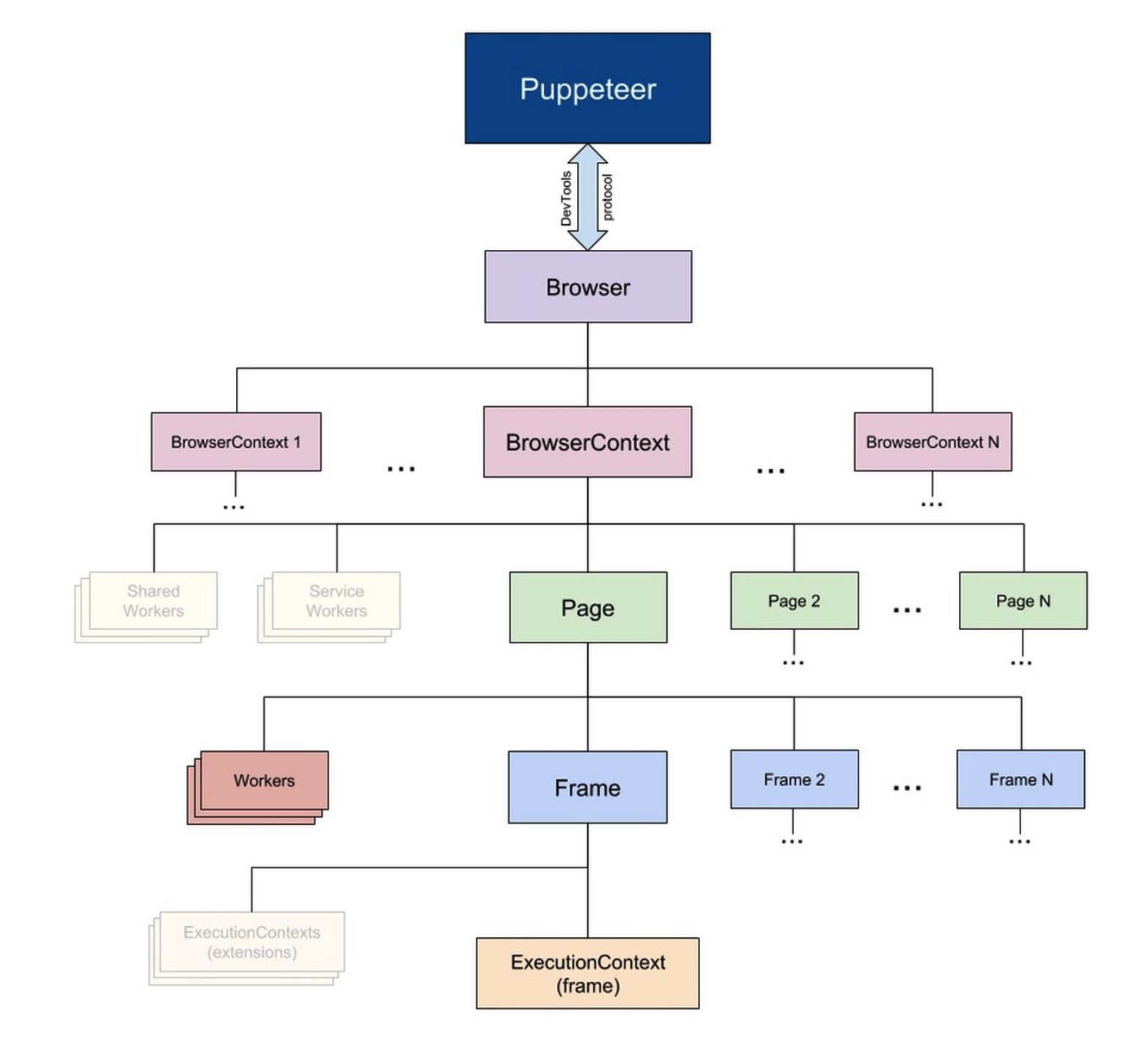
- Puppeteer 使用 DevTools 协议与浏览器通信
- Browser 实例可以拥有多个浏览器上下文
- BrowserContext 实例定义了一个浏览会话,并且可以拥有多个 Page
- Page至少有一个框架:主框架。iframe 可能还会创建其他框架
安装
使用 npm 安装 puppeteer:
1 | npm i puppeteer |
示例
1 | const puppeteer = require('puppeteer'); |
Puppeteer 实战
以下是获取某网站登录态的 Puppeteer 脚本。
1 |
|
脚本看起来还是简单易懂的。但实际开发过程中还是遇到了不少小坑:
问题1:网页跳转
这个案例中要登录的网站是 OAuth 方式,所以登录过程中是有一次页面跳转的,从我们要访问的网页跳转到 OAuth 提供方的网页。
解决办法:page.goto 方法的 waitUntil 参数传 networkidle2。即,等待足够长的时间保证页面跳转完成
问题2:无法找到页面元素
这个其实不是问题,但对 iframe 不了解的话往往会踩到这个坑。实际的网页结构比较复杂,可能有多个 iframe。如果 Puppeteer 脚本中找到指定的 html 元素,不妨看看你要访问的元素是否在 iframe 中!
解决办法:page.frames() 返回当前页面中的所有 frame。
问题3:Execution context was destroyed
如果你遇到以下报错,可以考虑使用另外一个 page 来规避问题。
1 | Execution context was destroyed, most likely because of a navigation. |
出错这种报错的原因很可能是因为导航,具体解决方法可以参考 Puppeteer执行上下文被破坏
问题4:调试技巧
技巧一:插入 debugger 启动调试器
1 | page2.evaluate(function () { |
技巧二:devtools 传 true 时打开 DevTools
1 | const browser = await puppeteer.launch({ |
问题5:获取 cookie
Puppeteer 模拟登录成功后可以获取网页登录态。登录态一般放在 cookie 中,使用 page.cookies() 获取页面 cookie (注意不是 document.cookie,这个无法返回 http only 的 cookie)
总结一下使用 Puppeteer 的大致步骤:
- CentOS 上安装 nodejs
curl --silent --location https://rpm.nodesource.com/setup_12.x | sudo bashyum -y install nodejs
- 使用 npm 安装 Puppeteer。如果遇到安装错误可以参考这里
npm i puppeteer
- 写 Puppeteer 脚本模拟登录,获取网站登录态。可以参考上面提供的脚本
- 写脚本访问网站的数据。这个因不同网站而异,这里不具体展开
- crontab 定时抓取数据。使用 crontab 时我经常把脚本路径弄错,注意 crontab 路径问题
crontab -e设置定时任务